Zwiad: Rozpoznanie przed rozpoczęciem automatyzacji
Spis treści
Prowadząc szereg szkoleń z automatyzacji testów w Javie przy użyciu narzędzi takich jak Selenium, RestAssured czy innych często słyszymy pytanie:
Jak zautomatyzować projekt X? Co automatyzować, a czego nie?
Pytania te przewijają się praktycznie zawsze. Odpowiedzią jest**„nie ma złotego klucza, to zależy od kontekstu".**
Kolejne wpisy będą dość nietypowe, ponieważ będą starać się pokazać elementy stałe, na które powinniśmy znaleźć czas i miejsce dla każdego projektu, który automatyzujemy. Wpisy będą pokazywać w jaki sposób inżynier testów powinien podejść do swojej pracy dla przykładowego kontekstu (projektu).
Kontekst -- czyli projekt, który będziemy automatyzować
GitHub jest pełen przykładowych projektów, które możemy użyć do nauki automatyzacji. Jednym z takich projektów jest projekt Marka Winteringhama (twórca bloga https://automationintesting.com) i Richarda Bradshawa o nazwie Restfull-booker-platform. I jego właśnie użyjemy.
Projekt został wybrany dlatego, że:
- Licencja twórców na to pozwala,
- Uzyskaliśmy zgodę Marka Winteringham'a,
- Mamy dostęp do kodu źródłowego https://github.com/mwinteringham/restful-booker-platform,
- Jest on oparty o nowoczesne frameworki, takie jak Spring czy React,
- Odzwierciedla w dużym stopniu prawdziwe środowisko rozwoju oprogramowania,
- Projekt posiada zdepojowaną wersję na https://automationintesting.online/#/, którą możemy używać do celów testowych i traktować jako deployment produkcyjny.
Założenia eksperymentu
Celem kolejnych wpisów będzie:
- Próba stworzenia pełnego procesu ciągłej integracji wraz z podstawowymi testami end-2-end dla projektu Restfull-booker-platform,
- Cały proces powinien być jak najbardziej zbliżony do prawdziwego projektu. Niestety, ze względu na różne ograniczenia, pewne rzeczy będziemy musieli uprościć lub założyć czysto teoretycznie.
Zły Początek
Mamy gotowy zdepojowany projekt, chyba czas zacząć go automatyzować? Ale jaką strategię przyjąć? Może zacznijmy od Selenium i testów logowania, a może od testów REST API?
Tutaj powinniśmy się zatrzymać. Jakiekolwiek pisanie kodu jest teraz niepoprawną czynnością. Od czego powinniśmy w takim razie zacząć?
Zwiad i poznanie projektu
**Przed rozpoczęciem automatyzacji każdego projektu powinniśmy go dobrze poznać.**Faza ta ma na celu zebranie jak największej ilości informacji. Zarówno technologicznie, jak i biznesowo. Jak to rozumieć?
Przejdźmy przez przykładowe pytania techniczne i biznesowe, na które każdy automatyk powinien poznać odpowiedź przed napisaniem pierwszej linii kodu.
Przykładowe pytania techniczne:
- Jak wygląda stos technologiczny systemu?
- Jak wygląda architektura projektu?
- Jak wygląda infrastruktura projektu - developerska, integracyjna i produkcyjna?
- Jak wygląda proces budowania projektu?
- Ile mamy baz danych i jakiego typu?
- Czy system wykorzystuje jakieś elementy trzeciej strony (z ang. third party)?
- Dlaczego zostały wybrane takie a nie inne biblioteki, frameworki?
- Jak jest depojowany system?
- Jak jest orkiestrowany system?
- Z jakiego systemu VCS i CI korzystamy?
- Jaki protokół wykorzystuje system do komunikacji zewnętrznej i wewnętrznej?
- Jakiego typu testy (unit, integration, kontraktowe, e2e, inne) pisze zespół (jeśli projekt już trwa)?
- Jakie są możliwości ładowania danych do systemu?
- Jakie przeglądarki wspieramy (jeśli to projekt webowy)?
- Jakie urządzenia wspieramy (jeśli jest to projekt na urządzenia mobilne/embedded)?
- Jak wygląda przepływ pracy podstawowych ścieżek w systemie?
Przykładowe pytania biznesowe/projektowe:
- Jaki jest cel projektu?
- Jaki jest cel systemu?
- Na ile jest planowany projekt?
- Gdzie znajduje się dokumentacja i w jakiej jest formie?
- Jakie zadanie pełni projekt?
- W jakiej metodologii pracujemy?
- Ile mamy czasu na testowanie manualne i automatyczne?
- Jaki mamy budżet na testowanie?
- Jak często i szybko musimy wydawać nowe wersje systemu?
- Jak duży jest zespół developerski?
- Skąd bierzemy wymagania?
- Czy musimy zachowywać traceablity między wymaganiami a testami?
- Jakie role mamy w systemie?
Czy to wszystkie pytania, na które powinniśmy znać odpowiedź? Oczywiście, że nie, jest ich znacznie więcej. Dodatkowo do części pytań powinniśmy zadać pytania cząstkowe.
W ramach pytań technicznych bardzo ważne jest też, aby zrozumieć podstawowe przepływy pracy z technicznego punktu widzenia dla developerskiej/produkcyjnej infrastruktury i architektury. Bo na niej właśnie będziemy pracować.

Przepływy pracy
Czym są przepływy pracy? Są to na przykład:
- Użytkownik chce się zarejestrować,
- Użytkownik chce się zalogować do systemu,
- Użytkownik chce zmodyfikować swoje dane w systemie.
Tester, który automatyzuje projekt musi szczególnie dobrze znać przepływy pracy od strony technicznej. Jak to rozumieć? Przejdźmy przez przykładowy przepływ pracy dla logowania dla hipotetycznego systemu:
- Użytkownik wykorzystując protokół HTTP wysyła żądanie logowania metodą POST,
- Żądanie trafia na serwer HTTP, np. nginx, następnie jest mapowane na serwis uwierzytelniający,
- Serwis uwierzytelniający sprawdza login i hasło w bazie danych np. PostgreSQL,
- Serwis uwierzytelniający tworzy token w ramach serwisu, który wykorzystuje Hazelcasta,
- Serwis uwierzytelniający zwraca token użytkownik i przekierowuje użytkownika na kolejny serwis.
Inny przykład jak przepływ pracy może wyglądać przedstawiono poniżej, tym razem w formie obrazka:
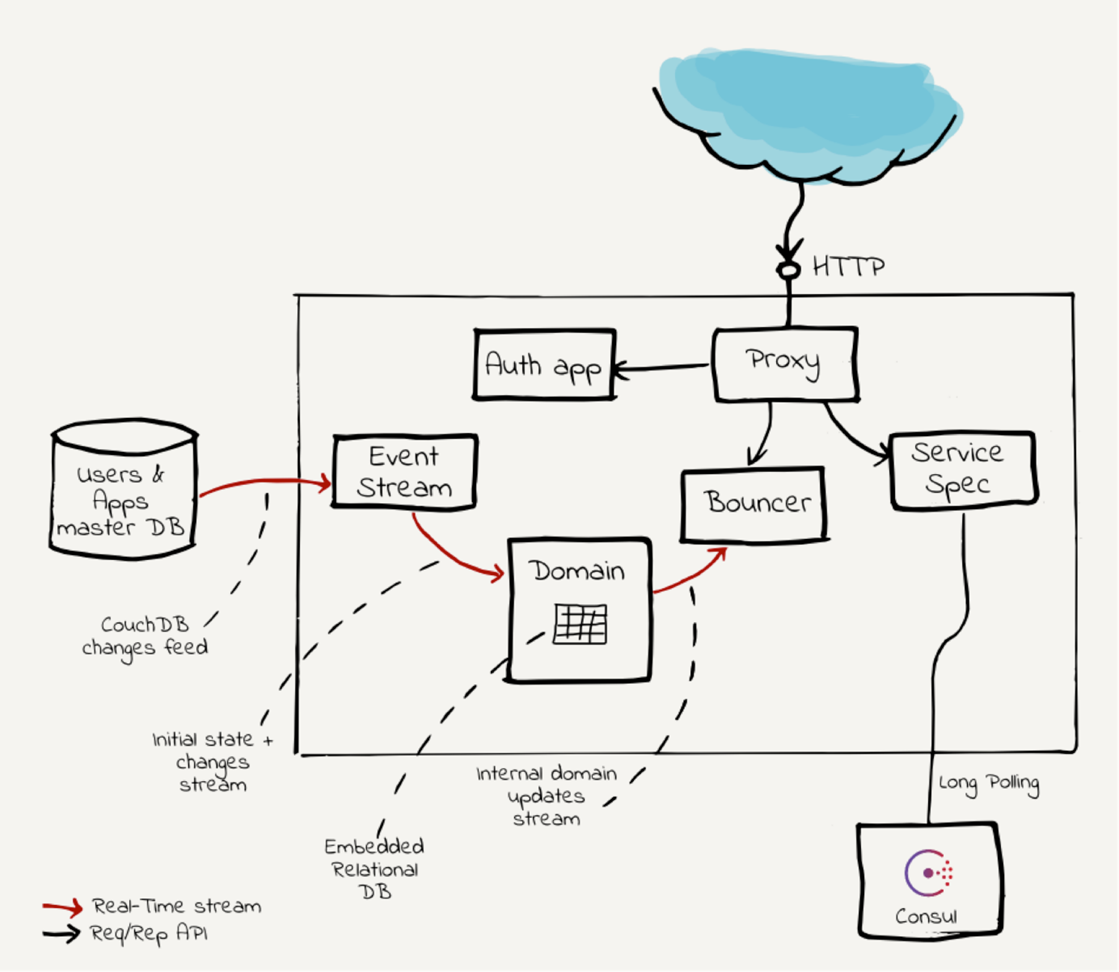
[Obrazek ze strony appsflyer.com].
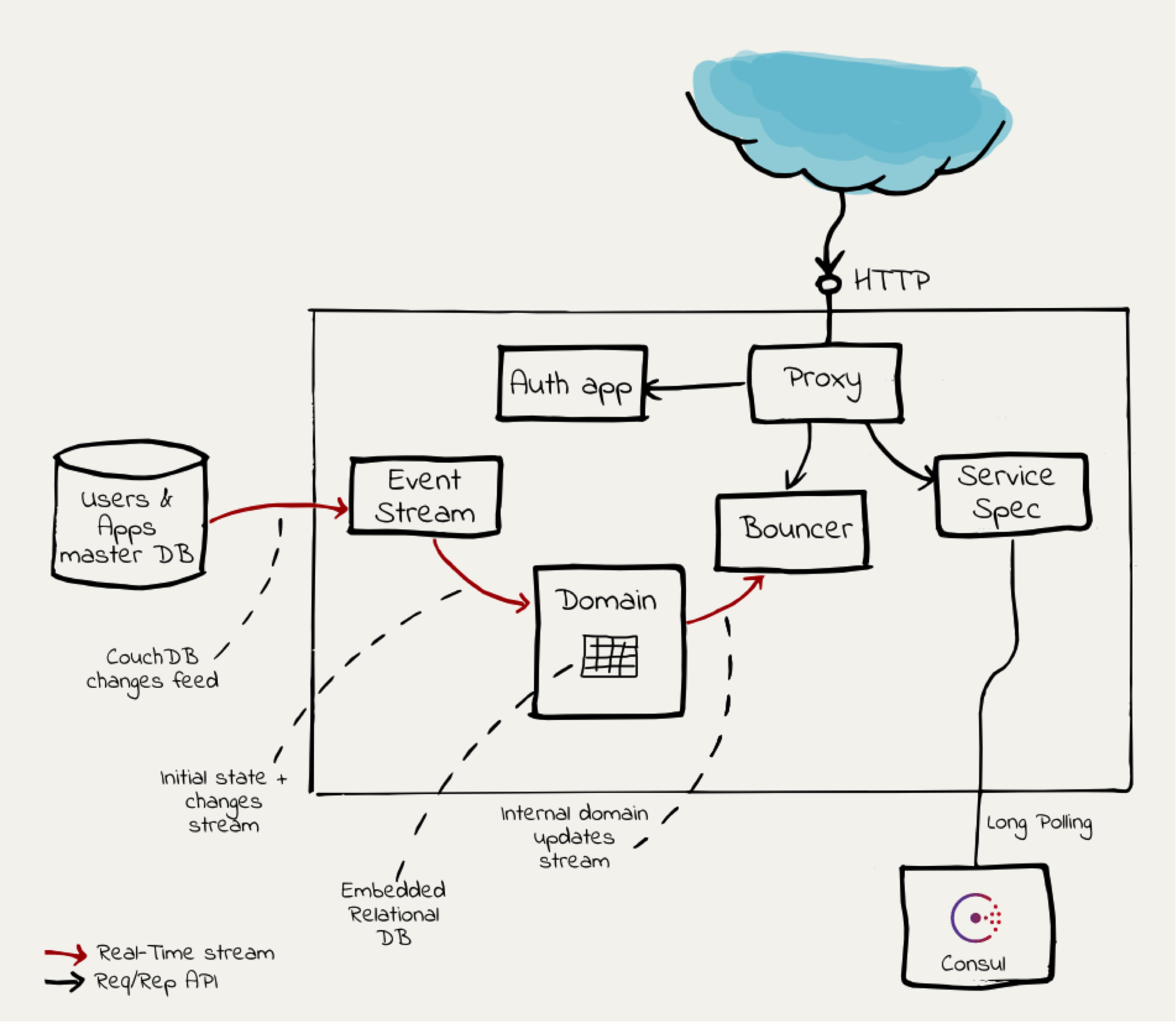{kind=link}
W zależności od projektu wiedza techniczna na temat przypływu pracy może znajdować się w kodzie, dokumentacji, mniej lub bardziej oficjalnej, lub tylko i wyłącznie w głowach twórców. Tak czy inaczej tester, który planuje wykonać automatyzację systemu musi tę wiedzę zdobyć i poznać, niezależnie od tego czy ten proces będzie wymagał czytania dokumentacji czy spędzenia kilku godzin z zespołem developerskim.
Tutaj jeszcze mały komentarz dla osób początkujących. Często w rozmowach między developerami słyszymy takie nazwy/kryptonimy jak Cassandra, Hazelcast, Kafka, RabbitMQ, transakcyjność, i inne. Wszystko to co mówią członkowie zespołu (developerzy, architekci, itd.) i jakiego języka używają powinno być dla nas jasne. Powinniśmy rozumieć na przykład dlaczego w systemie mamy dwie bazy danych, jedną MySQL, a drugą Cassandrę, w jakich przepływach pracy one uczestniczą i jaką rolę pełnią.
Poznając dalej system musimy go przetestować manualnie.
Dalsze poznanie projektu, czyli eksploracja
**Dobrze zaprojektowana i działająca automatyzacja systemu nie istnieje bez dobrze zaplanowanych i przeprowadzonych testów manualnych/eksploracyjnych.**Jeśli nie znasz systemu, jeśli go nie przetestowałeś, jeśli system, który automatyzujesz nie jest przetestowany manualnie -- nie bierz się za jego automatyzację.
Na powyższym zdaniu zakończymy dalsze rozważania na temat synergii między testami automatycznymi a manualnymi. Jest to temat rzeka, a my chcemy skupić się na innych aspektach. Podsumowując -- jeśli system nie był testowany manualnie i nie znamy jego stanu w tym kontekście, nie tworzymy testów automatycznych.
Początek, czyli zwiad
Mając podstawy teoretyczne przejdźmy do projektu Restfull-booker-platform.
Przechodzimy do poznania platformy, którą automatyzujemy.
Opis projektu Restfull-booker-platform
Po uzyskaniu zgody projekt został zforkowany i jest dostępny pod adresem:
https://github.com/ilusi0npl/restful-booker-platform
Restfull-booker-platform jest platformą usług internetowych do rezerwacji pokoi hotelowych.
Projekt składa się z kilku serwisów, do których należą:
- Assets -- Serwis jest odpowiedzialny za udostępnianie zasobów interfejsu użytkownika w przeglądarce, aby zapewnić użytkownikom łatwy dostęp do platformy restful-booker. W wolnym tłumaczeniu jest to nasze front-end webowy.
- Auth -- Serwis auth odpowiada za tworzenie, weryfikację i niszczenie tokenów używanych przez inne usługi do sprawdzania, czy są w stanie tworzyć, aktualizować lub usuwać treści. Jest to serwis, który odpowiada za autentykację.
- Booking -- Serwis ten jest odpowiedzialny za tworzenie, czytanie, aktualizowanie i usuwanie danych rezerwacji z bazy danych (w pamięci) w celu udostępniania ich innym serwisom.
- Branding -- Odpowiada za odczyt i aktualizację danych brandingowych (np. nazwa hotelu, opis hotelu, dane adresowe) z bazy danych (w pamięci) w celu udostępnienia ich stronom domowym (bez autentykacji) i administracyjnym (z autentykacją).
- Message -- Serwis jest odpowiedzialny za tworzenie, odczytywanie i usuwanie wiadomości z bazy danych (w pamięci) w celu udostępniania ich innym serwisom. Wiadomości są to po prostu informacje jakie użytkownik niezarejestrowany (bez autentykacji) może wysłać do administratora.
- Report -- Serwis jest odpowiedzialny za zestawienie informacji o różnych pokojach i łącznej cenie każdego pokoju dokonanej w rezerwacji.
- Room -- Serwis Room jest odpowiedzialny za tworzenie, odczytywanie, aktualizowanie i usuwanie danych o pokojach z bazy danych (w pamięci) w celu udostępniania ich innym serwisom.
Aktualna wersja projektu nie ma zewnętrznej bazy danych oraz serwisów lub usług trzecich, które pośredniczą w pracy systemu. Wynika to oczywiście z ograniczeń aktualnej implementacji. Wszystkie dane przechowywane są w pamięci danego konteneru. Co znaczy de-facto, że restart kontenera oznacza utratę danych. Wykorzystywana baza danych w ramach kontenerów to baza h2.
Wykorzystywany serwer HTTP to ngnix. Wszystkie serwisy backendowe systemu są napisane w Springu, zaś front-end jest napisany w Reactcie.
Każdy serwis ma swoje testy jednostkowe oraz testy integracyjne. Technologie użyte do testów to Jest, Spring, RestAssured, JUnit, WireMock.
System posiada dwie role użytkownika niezarejestrowanego oraz administratora.
System jest orkiestrowany za pomocą Dockera.
Na sam koniec powstaje pytanie:
Po co poznać system od strony technicznej? Jakie to ma znaczenie dla testów E2E, które chcemy wykonać?
O tym dowiesz się w kolejnych wpisach, kiedy przejdziemy do przygotowania i planowania automatyzacji wraz z zespołem.
Potrzebujesz więcej informacji?
Artykuł powstał na bazie kursu Automatyzacja testów z wykorzystaniem Selenium.
O Autorze
Nazywam się Mateusz Ciołek i od 2011 roku zajmuję się testowaniem oprogramowania ze specjalizacją w automatyzacji testów.
Dyskusja i komentarze
Masz pytania do tego wpisu? Może chcesz się podzielić spostrzeżeniami? Zapraszamy dyskusji na naszej grupie na Facebooku.