Uruchomienie testów na Jenkinsie - pipeline
Spis treści
Wstęp - Infrastructure as a code
W poprzednim artykule uruchomiliśmy testy na Jenkinsie tworząc najbardziej podstawowy plan na Jenkinsie jaki tylko się da. Przedstawione podejście jest niestety już dość przestarzale. Wynika to z faktu, że dzisiejszy świat rozwoju aplikacji jest dość dynamiczny. Ciągłe zmiany, ogromna ilość konfiguracji do zbudowania i przetestowania. To wszystko powoduje, że klasyczne podejście do planów na serwerze ciągłej integracji nie zdaje egzaminu.
W związku z czym powstała metodologia infrastructure as a code, z angielskiego kod jako infrastruktura. W podejściu IaC programiści/devopsi zarządzają i dostarczają stos technologii do aplikacji za pomocą skryptów (zapisanych w formie plików, tak jak normalny kod), zamiast używać ręcznego procesu konfigurowania. Infrastruktura jako kod jest czasami nazywana infrastrukturą programowalną lub programową.
Tyle tytułem wstępu.
Na Jenkinsie IaC jest rozwiązane przy pomocy rurociągów z ang. pipelines. Rurociąg to nic innego jak, plan którego konfiguracja zamknięta jest w skrypcie (pliku z kodem). Ale po kolei.

Czego potrzebujemy zanim zaczniemy?
To czego potrzebujemy nie różni się w zasadzie niczym od tego co zostało opisane w poprzednim artykule. Jedyna różnica to konieczność zaimplementowania skryptu, który „zaprogramuje" nam nasz pipeline. Skrypt ten na Jenkinsie jest zamknięty w ramach pliku o domyślnej nazwie tzw. Jenkinsfile. Oczywiście nazwa ta może być dowolna, jednakże dla uproszczenia będzie używać domyślnej nazwy.
Czym jest Jenkinsfile
Jenkinsfile to nic innego jak plik o nazwie Jenkinsfile , który nie posiada rozszerzenia. W ramach tego pliku znajduje się skrypt IaC. Jenkins domyślnie pozwala pisać skrypty IaC za pomocą języka Groovy (specyfikacja mówi dokładnie, że jest to język oparty o Grooviego, z modyfikacjami). Poniżej przykładowy kod Jenkinsfila:
pipeline {
agent any
stages {
stage('Stage One') {
steps {
echo 'Hi, it's JavaStart'
}
}
stage('Stage Two') {
steps {
input('Do you want to proceed?')
}
}
stage('Stage Three') {
when {
not {
branch "master"
}
}
steps {
echo "Let's start"
}
}
stage('Stage Four') {
parallel {
stage('Stage Unit Test') {
steps {
echo "Running the unit test..."
}
}
stage('Integration test') {
steps {
echo "Running the integration test..."
}
}
}
Na pierwszy rzut oka widzimy, że jest to kod. Wygląda on dość skomplikowanie, ale po przyjrzeniu się widzimy, że jest to opis planu. Składa się z kilku podstawowych części do których należą:
- Etapy zamknięte są w ramach funkcji z ang. stage,
- W ramach etapów (stage) , znajdują się krokiz ang. steps. Kroki definiują to co ma się wydarzyć,
- W ramach kroku może znajdować się jeden lub więcej komend do wykonania.
Jakie są możliwości opisu tego co znajduję się w Jenkinsfile? W zasadzie są one nie ograniczone. Więcej dowiesz z dokumentacji Jenkinsa do Jenkinsfileów.
Implementacja planu z Jenkinsfilem
Aby rozpocząć implementację musimy wpierw przypomnieć sobie, jakie etapy oraz kroki wykonujemy w prostym planie przedstawiony w poprzednim artykule. I tak mamy:
- Pobranie repozytorium z kodem testów z ang. repository checkout,
- Uruchomienie testów,
- Wygenerowanie raportu,
Należy zaznaczyć , że w ramach etapu uruchomienia testów zawieramy wywołanie dwóch komend.
Zbudowanie kodu testów:
mvn clean install -DskipTests
Uruchomienia testów:
mvn test
Implementację zaczynamy od utworzenia nowego planu na Jenkinsie. Analogicznie jak poprzednio po zalogowaniu do Jenkinsa, klikamy na New Item:
Z listy dostępnych projektów wybieramy Pipeline. Następnie wpisujemy samopsującą się nazwę projektu na przykład „Selenium_Acceptance_Tests_Pipeline_Project". Tak jak na obrazku poniżej:
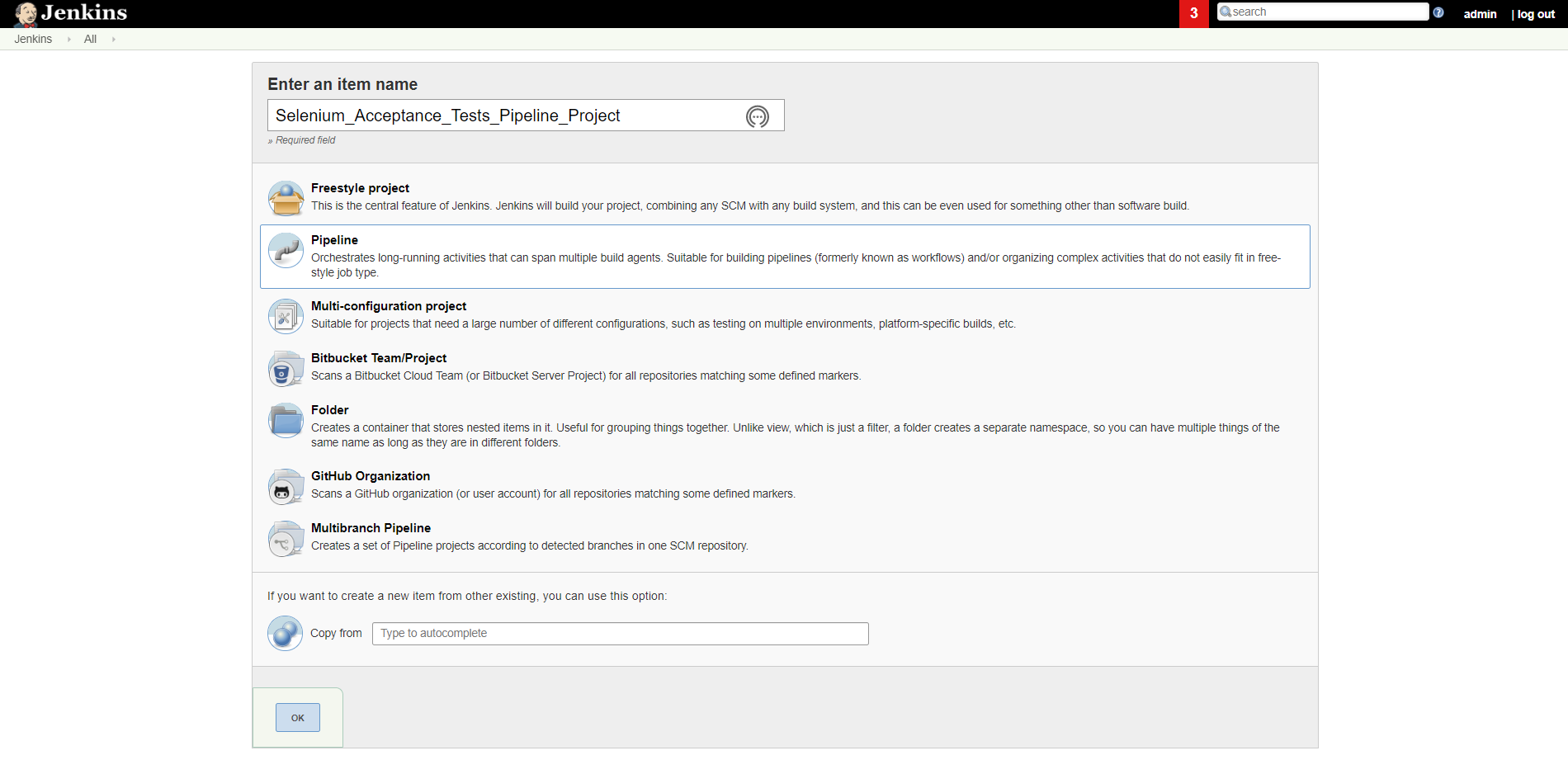
Mając wpisaną nazwę planu naciskamy przycisk OK.
Zostaje wyświetlona konfiguracja planu, tak jak na obrazku poniżej:
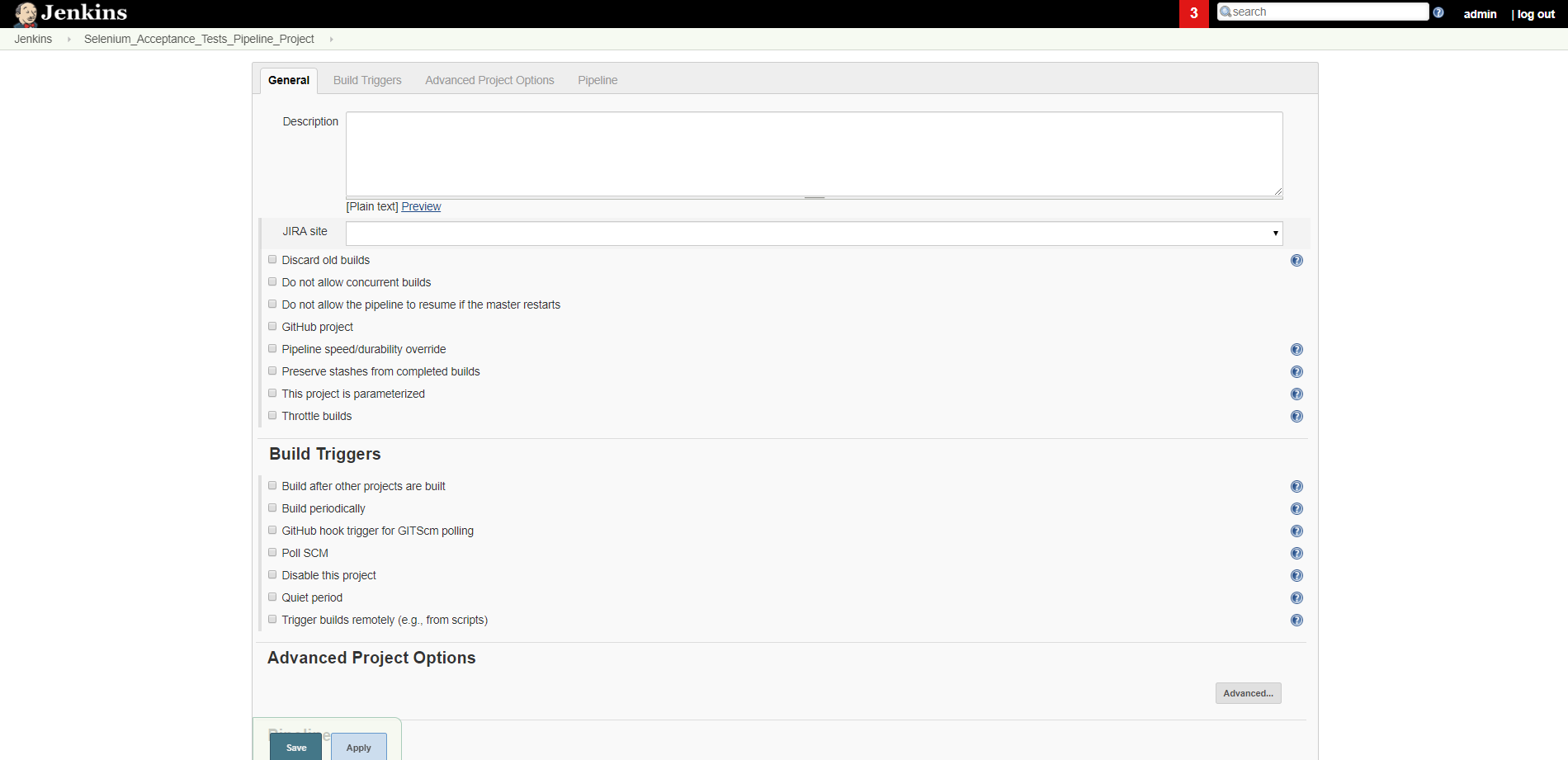
Na formularzu strony dostępne są sekcje:
- General -- odpowiada za wysoko poziomową konfigurację projektu,
- Build Trigger -- pola w tej sekcji definiują warunki, kiedy projekt ma być budowany. Na przykład co 2 godziny lub z każdą zmianą w repozytorium,
- Advanced Project Options-- Aktualnie sekcja pusta, domyślnie pozwala tylko na zmianę wyświetlanej nazwy projektu/planu,
- Pipline -- W sekcji tej definiujemy właściwy kod IaC,
To co może zdziwić to brak sekcji odpowiadającej VCS (Version Control System), czyli repozytorium. Wynika to z faktu, że checkout repozytorium, możemy zapisać w formie kodu Grooviego, komendy shellowej lub skorzystać zPipeline from the script(o tym za chwilę). Dlatego Jenkins nie przewiduje takiej sekcji osobno dla podstawowej konfiguracji.
Mając gotowy plan musimy zastanowić się gdzie chcemy przechowywać kod pipelinu , czy kod IaC. Jak widzimy Jenkins domyślnie wyświetla nam pole Script w sekcji Pipeline.
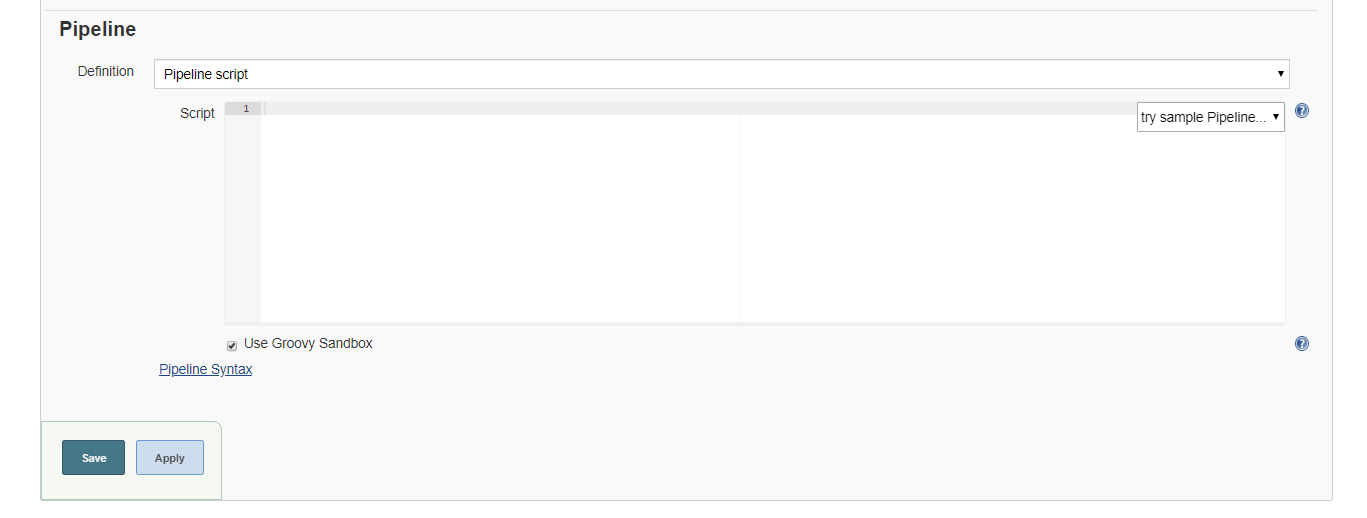
Możemy tam właśnie wpisać kod i po wszystkim. To rozwiązanie jest hybrydą klasycznego „klikanego" podejścia z IaC, dlatego nie jest polecane dla więcej niż bardzo prostych projektów. Drugim rozwiązaniem jest umieszczenie pliku z kodem dla infrastruktury w repozytorium. I tutaj właśnie wchodzi Jenkinsfile. To właśnie rozwiązanie zostanie wykorzystane.
Należy jeszcze wyjaśnić z jakiego repozytorium będzie korzystać. Odpowiedzią na to pytanie jest oczywiście repozytorium z kodem testów. Właśnie tam umieścimy Jenkinsfila.
Przejdźmy zatem do konfiguracji.
Zacznijmy od wybrania w polu Definition w sekcji Pipeline , wartości Pipeline script from SCM. Tak jak na obrazku poniżej:
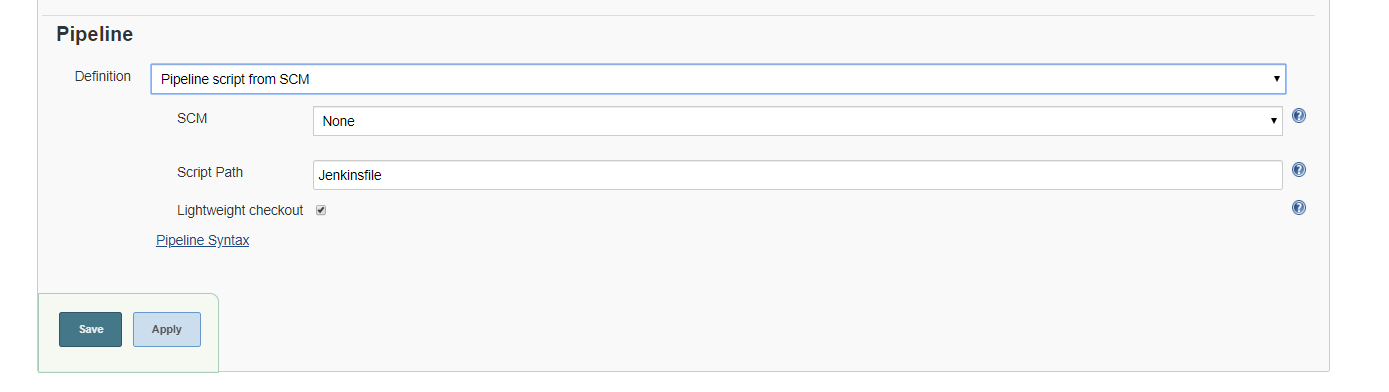
Zostały nam wyświetlone nowe pola:
- SCM -- odpowiadające ze konfigurację repozytorium,
- Script Path-- określające ścieżkę do Jenkinsfile.
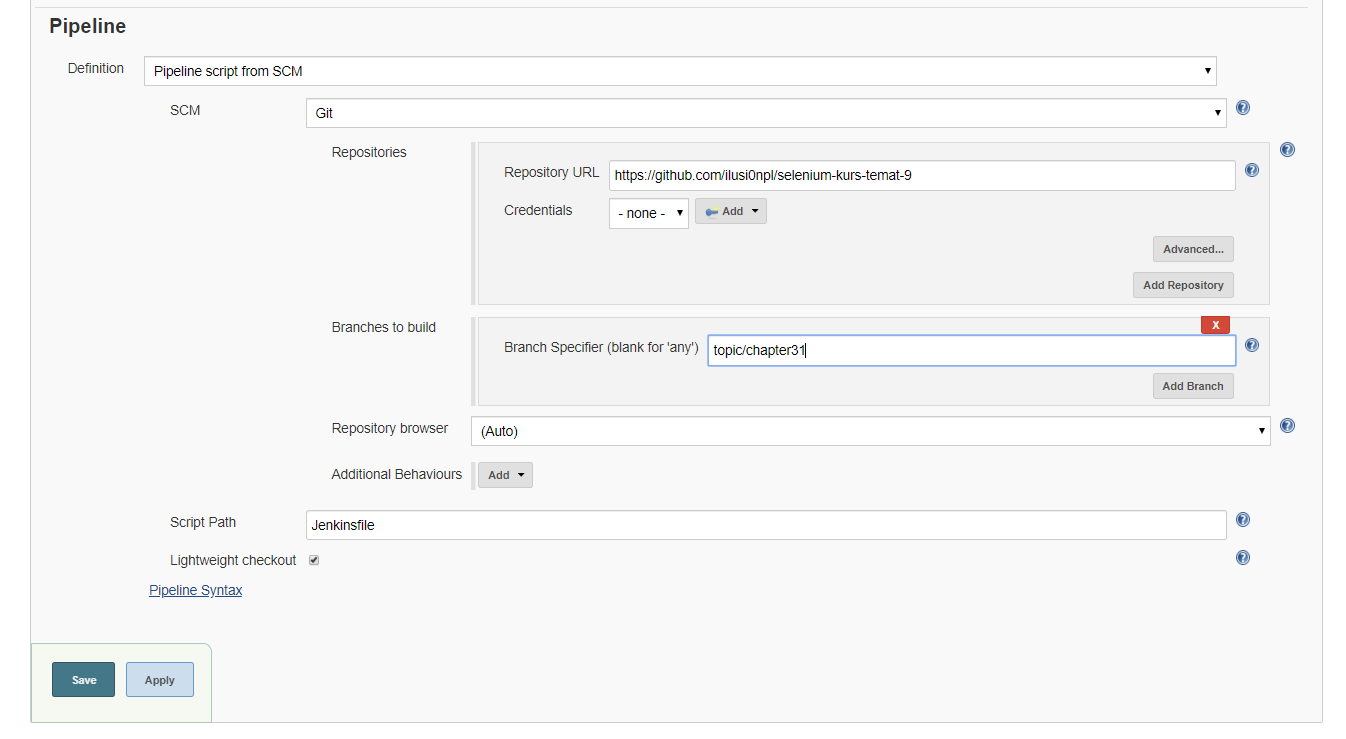
Kontynuując, w polu SCM wybieramy Giti analogicznie jak dla planu pierwszego podajemy wartości dla pól:
- W polu Repository URL wpisujemy adres repozytorium - https://github.com/ilusi0npl/selenium-kurs-temat-9
- W polu Branches to build wpisujemy wartość topic/chapter30, ponieważ będzie używać specyficznej gałęzi.
- Pozostałe pola pozostawiamy bez zmian.
Mając gotową konfigurację repozytorium, możemy przejść do tworzenia Jenkinsfila.
Implementacja Jenkinsfile
Jak już wiesz, z poprzednich akapitów, Jenknsfile utworzymy w ramach repozytorium z testami. Gdzie go umieścić? Dla uproszenia umieścimy go w główmy folderze projektu. Tak jak na obrazu poniżej:
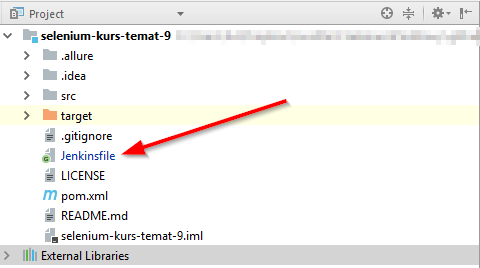
Jak widzisz plik ten nie ma rozszerzenia i nazywa się po prostu Jenkinsfile.
Mając stworzony plik możemy go wypełnić treścią poniżej:
pipeline {
agent any
stages {
stage('Build test code') {
steps {
sh 'mvn clean install -DskipTests'
}
}
stage('Execute test') {
steps {
sh 'mvn test'
}
}
stage('Generate allure report') {
steps {
script {
allure([
includeProperties: false,
jdk : '',
properties : [],
reportBuildPolicy: 'ALWAYS',
results : [[path: 'target/allure-results']]
])
}
}
}
}
}
* Uwaga - testy z kursu na gałęzi topic/chapter30 są skonfigurowane w następujący sposób:
* Uruchomią testy lokalnie, bez Selenium GRID przy użyciu lokalnych driverów,
* Drivery mają podane następujące ścieżki:
chrome.driver.location=C:/drivers/chromedriver.exe
firefox.driver.location=C:/drivers/geckodriver.exe
ie.driver.location=C:/drivers/IEDriverServer.exe
O tym jak skonfigurować framework pod Selenium GRID z Jenkinsem oraz utworzyć odpowiednią infrastrukturę jako kod, dowiesz się w kolejnych lekcjach.
Taka a nie inna forma konfiguracji wynika z formy kursu, czyli nauki krok po kroku.
Wracając do kodu pipelina. Analizując treść od początku:
pipeline { // początek definicji pipeline
agent any // określenie na jakim agencie ma wykonywać się kod
stages { // początek definicji etapów
Uwaga: jeśli nie wiesz co to jest agent, zapoznaj się z artykułem.
Dalej kod mamy podzielony na trzy etapy, etap budowania kodu o nazwie Build test code:
stage('Build test code') {
steps {
sh 'mvn clean install -DskipTests'
}
}
W ramach którego wywołana jest komenda shellowa clean install z parametrem.
Etap uruchomienia testów o nazwie Execute test:
stage('Execute test') {
steps {
sh 'mvn test'
}
}
Jak widać kod powyżej nie różni się niczym w konstrukcji od poprzedniego etapu. Jedyna różnica to nazwa Execute testoraz komenda do uruchomienia.
Ostatni stageto generowanie wyników:
stage('Generate allure report') {
steps {
script {
allure([
includeProperties: false,
jdk : '',
properties : [],
reportBuildPolicy: 'ALWAYS',
results : [[path: 'target/allure-results']]
])
}
}
}
Tutaj kod jest troszeczkę bardziej skomplikowany. Przede wszystkim mamy sekcje script w ramach której znajduje się sekcja **allure.**Skąd wzięliśmy wskazany kod? Odpowiedź na to pytanie jest bardzo prosta.
Przede wszystkim jak wiesz z poprzedniego artykułu w ramach serwera ciągłej integracji z którego korzystamy, mamy zainstalowany plugin do Jenkinsa dla Allure. Plugin pozwala na użycie go w ramach pipelinu. Opis jego użycia dostępny jest w dokumentacji. Wystarczyło wziąć pierwszy dostępny przykład.
Tłumacząc sam kod sekcji allure to definiujemy w niej:
- includeProperties -- czy chcemy dołączyć właściwości definiujące konfigurację allura. Wartość ustawiona jest na false, ponieważ nie dołączamy żadnych properties.
- jdk -- definiuje JDK Javy jaki plugin ma użyć do generacji raportu. Pusta wartość oznacza domyślną na agencie,
- properties -- definiuje właściwości (properties),
- reportBuildPolicy -- definiuje kiedy ma być generowany raport, na przykład tylko przy porażce testów. Aktualna wartość ALWAYS oznacza, że raport ma się generować zawsze,
- results -- definiuje lokalizację wyników z testów, na podstawie których ma być wygenerowany raport.
Mając gotowy Jenkinsfilezapisujemy go i dodajemy do repozytorium.
W konfiguracji planu musimy jeszcze zdefiniować ścieżkę do utworzonego przez nas Jenkisfilu.
Ścieżkę definiujemy w polu Script Path, tak jak na obrazku poniżej:
Ponieważ, utworzony Jenkinsfile znajduje się w głównym katalogu repozytorium oraz jego nazwa to Jenkinsfile to nie musimy nic zmienić w polu Script Path.
Po skończonej konfiguracji możemy zapisać i uruchomić plan.
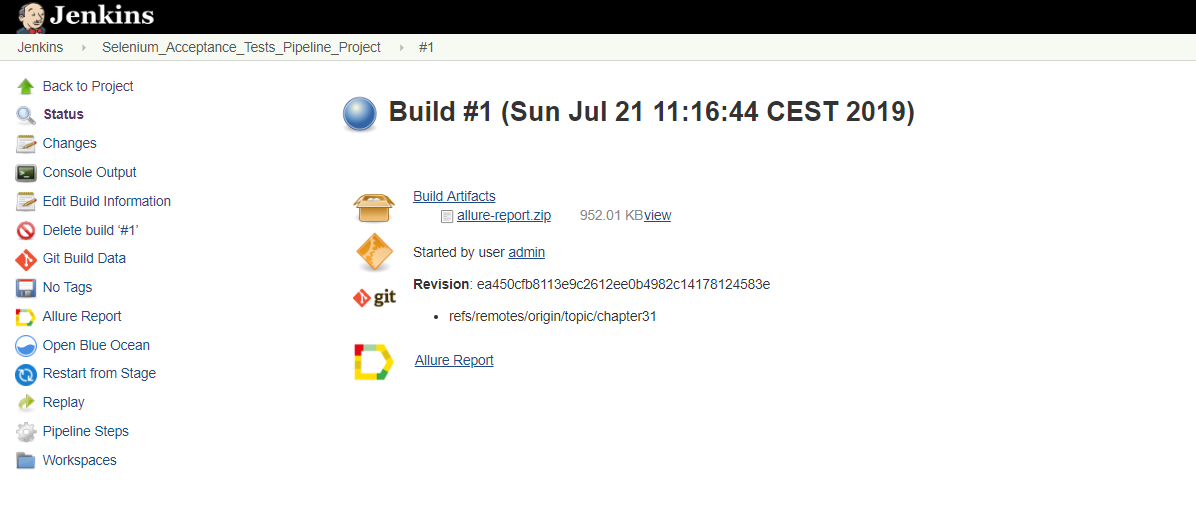
Na tym kończy się nasza konfiguracja.
Co dalej
Udało nam się skonfigurować pierwszy prosty pipeline na Jenkinsie. To co możemy definiować w pipeline to dopiero początek. Wprowadzenie testów na serwer ciągłej integracji wymusi na frameworku, który budujemy szereg ulepszeń i zmian, ale o tym dowiesz się w kolejnych artykułach.
Potrzebujesz więcej informacji?
Artykuł powstał na bazie kursu Automatyzacja testów z wykorzystaniem Selenium!
O Autorze
Nazywam się Mateusz Ciołek i od 2011 roku zajmuję się testowaniem oprogramowania ze specjalizacją w automatyzacji testów.
Dyskusja i komentarze
Masz pytania do tego wpisu? Może chcesz się podzielić spostrzeżeniami? Zapraszamy dyskusji na naszej grupie na Facebooku.