Metoda hashCode()
Metoda hashCode() służy w Javie do zwrócenia (w miarę) unikalnej wartości liczbowej typu int dla każdego unikalnego obiektu. Istnieje kontrakt mówiący o tym, że dwa obiekty, których porównanie przy pomocy metody equals() zwraca true, to metoda hashCode() powinna zwracać dla tych obiektów taką samą wartość.
Choć brzmi to bardzo prosto, to w praktyce zwrócenie unikalnej wartości dla każdego obiektu nie jest tak oczywiste.
Domyślna implementacja
Metoda hashCode() jest dziedziczona z klasy Object i domyślnie powinna zwrócić unikalną wartość dla każdego obiektu. Jeśli jej nie nadpiszemy, to zwróci ona różne wartości nawet dla obiektów, które pod względem przechowywanych wartości są równe. Spójrzmy na przykład.
public class Product {
private String name;
private double price;
public Product(String name, double price) {
this.name = name;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
}
Po utworzeniu dwóch identycznych obiektów ani ich porównanie przez metodę equals() ani wartości zwracane przez metody hashCode() nie będą równe.
public class HashExample {
public static void main(String[] args) {
Product prod1 = new Product("Czekolada", 2.99);
Product prod2 = new Product("Czekolada", 2.99);
System.out.println(prod1.equals(prod2));
System.out.println(prod1.hashCode()); //2018699554
System.out.println(prod2.hashCode()); //1311053135
}
}
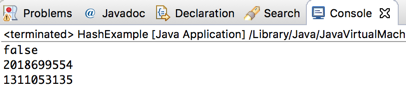
Domyślna metoda hashCode() wykorzystuje do wyliczenia zwracanej wartości adres obiektu w pamięci. Ta sama wartość jest wykorzystywana w domyślnej metodzie toString(), ale w postaci szesnastkowej.

Własna implementacja
Przy nadpisywaniu metody hashCode() powinniśmy uwzględnić wszystkie pola klasy. Jeśli są to wartości prostych typów liczbowych, to możemy je wykorzystać bezpośrednio. W przypadku typów obiektowych powinniśmy wywołać ich metodę hashCode() i posłużyć się zwracaną przez nią wartością (deep hashCode). Dla naszej poprzedniej klasy metoda taka może wyglądać tak jak poniżej:
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((name == null) ? 0 : name.hashCode());
long temp;
temp = Double.doubleToLongBits(price);
result = prime * result + (int) (temp ^ (temp >>> 32));
return result;
}
Do wyliczenia zwracanej wartości wykorzystujemy zarówno wartość name i price . Istnieją różne algorytmy pozwalające wyliczyć hashCode, jednak wszystkie łączy to, że powinniśmy wykorzystać w nich liczbę pierwszą (powyżej 31), następnie wykonać przesunięcia bitowe. Powyższa metoda została wygenerowana przy pomocy eclipse (Source > generate hashCode i equals), nieco inaczej wyglądałoby to w IntelliJ IDEA, czy NetBeansie.
Konsekwencje błędnej implementacji
Pierwszym pytaniem, jakie musimy sobie zadać, to gdzie właściwie metoda hashCode jest wykorzystywana? Otóż przede wszystkim we wszystkich strukturach danych, które opierają się na tablicach mieszających (hashtable), np. zbiorach (HashSet), czy mapach (HashMap). Metoda hashCode() wykorzystywana jest m.in. do wykrywania kolizji podczas wstawiania obiektów. W przypadku błędnej implementacji metod hashCode() i equals(), pozornie różne obiekty mogą być traktowane jako duplikaty.
Wróćmy to klasy Product i dodajmy do niej błędne metody hashCode() i equals().
import java.util.Objects;
public class Product {
private String name;
private double price;
public Product(String name, double price) {
this.name = name;
this.price = price;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Product product = (Product) o;
return Objects.equals(name, product.name);
}
@Override
public int hashCode() {
return Objects.hash(name);
}
@Override
public String toString() {
return "Product{" +
"name='" + name + '\'' +
", price=" + price +
'}';
}
}
Do wyliczenia wartości hashcodu i wyniku metody equals() wykorzystywane jest tylko pole name. Wstawiając teraz kilka obiektów do zbioru, struktura będzie działała niepoprawnie:
import java.util.HashSet;
public class Test {
public static void main(String[] args) {
HashSet<Product> set = new HashSet<>();
set.add(new Product("mleko", 2.8));
set.add(new Product("mleko", 3.2));
System.out.println(set);
}
}
Zbiór typu HashSet działa w taki sposób, że w pierwszej kolejności na podstawie hashcodu wyliczany jest kubełek, do którego ma trafić dana wartość (kubełek to w praktyce inna struktura danych, np. tablica, albo lista). Załóżmy, że wyliczony został kubełek nr 3. Ponieważ w kubełku tym nie ma w tym momencie żadnego obiektu, to trafia tam mleko za 2.8.
Przy wstawianiu drugiego produktu, pomimo że ma on inną cenę, to ponownie zostaje wyliczony taki sam hash, bo brana jest pod uwagę tylko nazwa, a więc produkt będzie wstawiany do tego samego kubełka. W tym momencie wykorzystywana jest dodatkowo metoda equals() , aby sprawdzić, czy obiekt ten nie jest duplikatem. Nasza metoda equals() przy porównywaniu obiektów wykorzystuje wyłącznie pole name , a więc obiekty zostają potraktowane jako duplikaty i drugi obiekt, choć w praktyce jest różny, to nie zostaje wstawiony do kubełka numer 3, a tym samym w zbiorze będzie tylko jeden obiekt. Taka sytuacja może mieć miejsce wtedy, gdy do klasy dodajemy jakieś pola po czasie, ale zapominamy o zaktualizowaniu metod equals() i hashCode().
Podobny problem może wystąpić także w drugą stronę, tzn. gdy np. przez pomyłkę w metodzie hashCode() uwzględnimy wszystkie pola, a w praktyce i na podstawie wymagań biznesowych jako obiekty równe uznajemy takie, które mają identyczną nazwę (nie bierzemy pod uwagę ceny).
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Product product = (Product) o;
return Objects.equals(name, product.name);
}
@Override
public int hashCode() {
return Objects.hash(name, price);
}
Przy takiej kombinacji metod equals() i hashCode() jeżeli do zbioru będziemy wstawiali dwa obiekty:
new Product("mleko", 2.8);
new Product("mleko", 3.2);
To choć na podstawie metody equals() możemy stwierdzić, że są one sobie równe, to ze względu na wyliczoną przez metodę hashCode() wartość trafią one do różnych kubełków, a więc metoda equals() nie będzie wcale wykorzystana do ich porównania. Chociaż tym razem oczekiwalibyśmy, że w zbiorze będzie tylko jeden obiekt, to w rzeczywistości zostaną do niego wstawione oba.
Z tego powodu ważne jest to, żeby metody equals() i hashCode() zawsze spełniały kontrakt mówiący o tym, że jeżeli dwa obiekty są sobie równe w rozumieniu porównania przez equals() , to metoda hashCode() powinna dla nich zwrócić tę samą wartość.
Dyskusja i komentarze
Masz pytania do tego wpisu? Może chcesz się podzielić spostrzeżeniami? Zapraszamy dyskusji na naszej grupie na Facebooku.